
Many organizations use AI every day – copilots, assistants, and even agents. But enterprise AI is different: it has to run reliably, integrate with real systems, meet standards, and keep working as data changes.
That reliability comes from one thing more than anything else: ML pipelines.
What is a Machine Learning (ML) pipeline?
An ML pipeline is the repeatable workflow that moves an AI capability from idea → data → model → production → monitoring.
Think of it as the “factory line” for machine learning – so results don’t depend on a single person, a single notebook, or a one-time setup.
Why ML pipelines matter in Enterprise AI
A pipeline creates the structure that makes AI dependable:
- Consistent: the same steps happen the same way every time – so results aren’t dependent on who ran the notebook or which manual steps they remembered.
- Traceable: inputs, features, model versions, and changes can be tracked – so when performance shifts, teams can quickly identify what changed and why.
- Collaborative: the pipeline becomes a shared, versioned workflow for data engineers, analysts, data scientists, and ML engineers – keeping handoffs clean and standards consistent.
- Relatively fast: teams can iterate, retrain, and deploy improvements quickly – without rebuilding the process from scratch.
- Lower risk: automated checks, approvals, and monitoring reduce surprises in production and help prevent silent failures
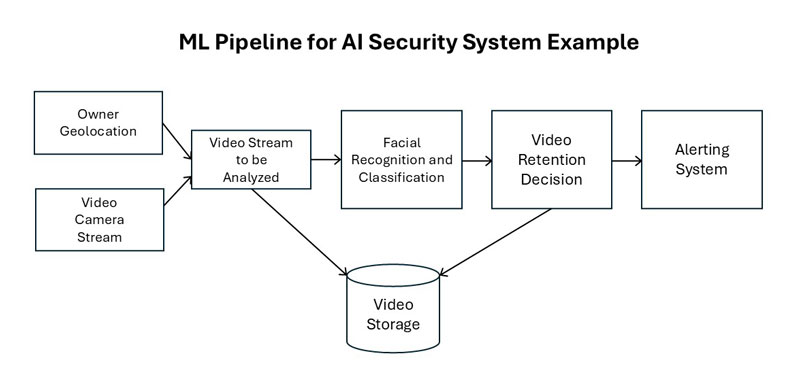
In short: pipelines turn experiments into systems. Here’s a sample for an AI video security process-
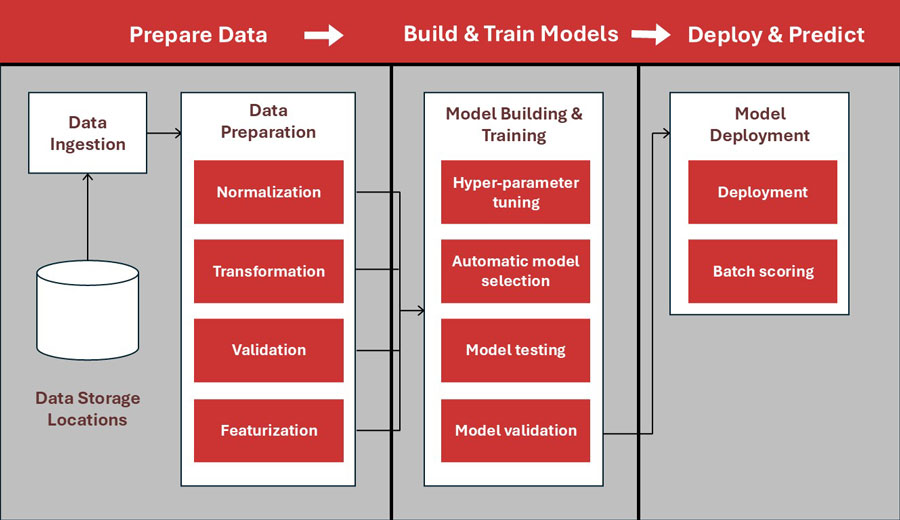
The core stages of a practical ML pipeline
A modern enterprise pipeline typically includes these stages:
- Data ingest and validation
Pull data from approved sources, then validate it (types, ranges, missing values, drift). This prevents silent breakage before it reaches the model. - Feature prep
Clean, transform, and create features in a consistent way. If feature logic isn’t repeatable, the model isn’t repeatable. - Training and evaluation
Train on a defined dataset/version, evaluate against baseline metrics, and compare performance to prior releases. - Approval and deployment
Promote only what passes agreed checks (performance, bias/quality thresholds, security/compliance requirements). Deploy via repeatable infrastructure—not manual clicking. - Monitoring and feedback
Watch performance in production: prediction quality, drift, latency, failures, and business impact. Feed learnings back into retraining.
The real “gotcha”: models degrade
Even a great model will fade over time because:
- customer behavior changes,
- products change,
- markets change,
- upstream systems change, and
- data distributions drift
A pipeline makes this normal – because it assumes change will happen and builds the response into the system.
A simple rule of thumb
If an AI initiative matters to revenue, operations, customer experience, or risk management, it needs a pipeline. Without one, you don’t have an enterprise AI capability – you have a fragile demo.
ML pipelines are how enterprises make AI reliable, repeatable, and safe to scale. They reduce risk, improve speed, and keep performance from degrading as the world changes.